
Over the past few months, we have deployed, debugged, and studied KBLaM (Knowledge Base augmented Language Model) in depth. Proposed by Microsoft Research in 2025, KBLaM injects structured knowledge directly into a pretrained LLM using a sentence encoder and linear adapters. It converts a knowledge base into continuous key–value vectors (knowledge tokens) and fuses them into the LLM through a modified rectangular attention mechanism, enabling the model to answer knowledge‑dependent questions without external retrieval. This article reviews KBLaM’s principles and experiments, summarizes our deployment experience on domestic servers, lays out the next training plan, discusses Chinese localization, and proposes improvements for KBLaM.
I. Review of KBLaM Theory and Experiments
1.1 Model design
The core idea is to map knowledge base triples $\langle \text{name},\,\text{property},\,\text{value} \rangle$ into vectors matching the LLM’s key–value cache size, called knowledge tokens. The process is:
- Knowledge encoding. For each triple, a pretrained sentence encoder $f(\cdot)$ maps “name's property” and “value” into base key vector $k_m = f(\text{property}_m\,\text{of}\,\text{name}_m)$ and value vector $v_m = f(\text{value}_m)$. Linear adapters then project them to each layer’s key/value spaces: $\tilde{k}_m = \tilde{W}_K k_m$, $\tilde{v}_m = \tilde{W}_V v_m$. Each knowledge token carries key/value vectors for $L$ layers and can be consumed directly by attention at different depths.
- Rectangular attention. At inference, the model feeds $N$ prompt tokens and $M$ knowledge tokens into attention. To avoid $O((N+M)^2)$ complexity, knowledge tokens do not attend to each other; prompt tokens may attend to prior prompts and to all knowledge tokens, yielding an $(M+N)\!\times\!N$ rectangular attention matrix. For layer $l$, each output vector $\tilde{y}_n$ sums two parts: a weighted sum over knowledge values (weights from similarity between the query and knowledge keys) and a standard self‑attention part among prompt tokens. This design makes compute and memory grow linearly with the number of triples, advantageous when $M\gg N$.
- KB instruction tuning. Because the sentence encoder and the LLM live in different semantic spaces, the paper trains only linear adapters and an extra query head via instruction tuning. Using a synthetic KB generated by GPT (≈45k names, 135k triples), it maximizes $\log p_\theta(A\mid Q,KB)$ without changing LLM weights. Trained with AdamW for 20k steps on a single A100, the model learns retrieval behavior and refusal strategies without degrading its original reasoning ability.
To visualize the overall flow, Figure 1 shows the offline/online stages: offline we build/encode the KB into knowledge tokens; online we feed tokenized prompts plus rectangular attention into the LLM to retrieve and generate answers. The pseudo‑code below illustrates how a single attention layer fuses knowledge tokens with prompt tokens:
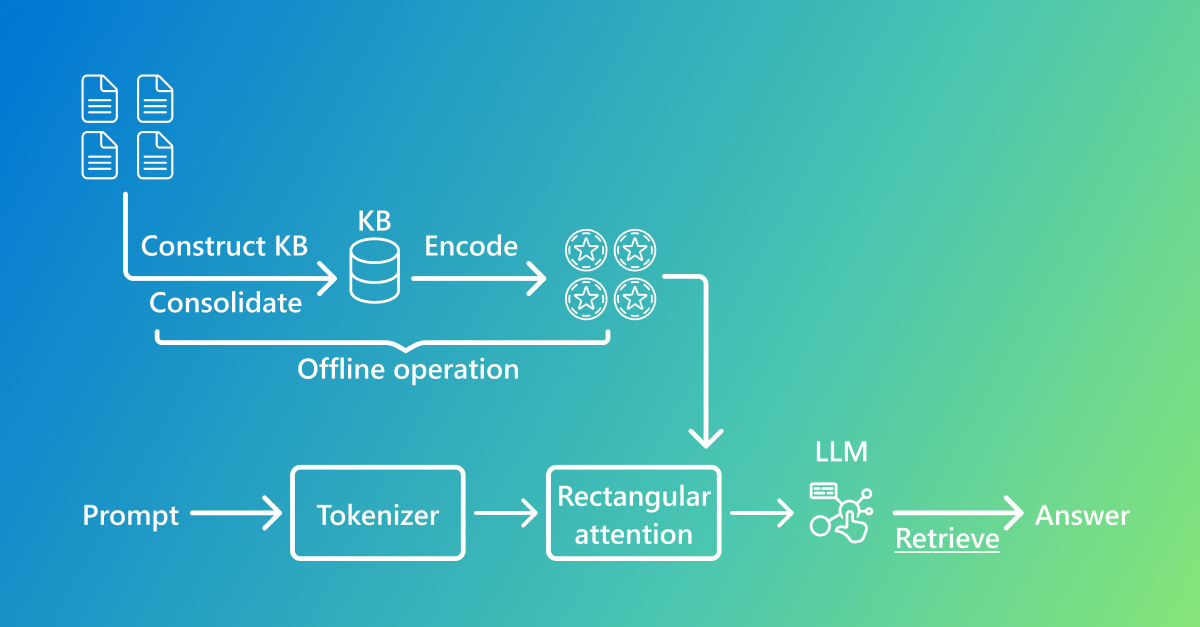
Figure 1. Offline we build/encode a KB to generate knowledge tokens; online rectangular attention fuses prompts and knowledge before the LLM generates an answer.
1.3 Rectangular attention pseudo‑code
def rectangular_attention(Q, K_kb, V_kb, K_text, V_text):
"""
Q: query matrix from prompt tokens, shape (N, d)
K_kb, V_kb: knowledge keys/values, shape (M, d)
K_text, V_text: self‑attention keys/values for prompt tokens
Returns: fused output that combines knowledge and prompt
"""
# Attention over knowledge tokens
attn_kb = softmax(Q @ K_kb.T / sqrt(d))
output_kb = attn_kb @ V_kb
# Self‑attention among prompt tokens
attn_text = softmax(Q @ K_text.T / sqrt(d))
output_text = attn_text @ V_text
# Combined output
return output_kb + output_text
1.2 Experimental results
- Retrieval accuracy and interpretability. Attention scores act as implicit retrieval signals: question words attend to the correct knowledge tokens for the asked triples. On synthetic and Enron datasets, KBLaM maintains precise top‑1/top‑5 retrieval under large KBs.
- Question answering quality. On short‑answer, multi‑entity, and open‑ended QA, KBLaM’s answer quality (BERTScore or GPT‑4 ratings) matches in‑context concatenation of all triples, while greatly reducing memory. For KBs with >10k triples, in‑context learning becomes infeasible due to $O((KN)^2)$ memory, but KBLaM remains stable.
- Refusal behavior. KBLaM can detect when the KB lacks relevant triples and politely refuse; as KB size grows, false‑refusal rises more slowly than with in‑context learning.
- Limitations. Fixed‑length vectors for triples lose precise numerics/names; synthetic KBs may not match real‑world distributions, harming generalization; future work includes multi‑hop instructions, controllable compression, and building synthetic KBs from real data.
II. Deployment Journey on Domestic Servers
Our environment uses Kylin v10 OS and eight Ascend 910B NPUs with no Internet access due to compliance. This differs greatly from the GPU + GPT/ada‑002 setup assumed by the paper, leading to several key adaptations:
- Synthetic KB and instruction data generation. The original used GPT to create random names and properties. Without OpenAI access, we switched to local LLMs in an offline setting. Tests on Windows + RTX 2080 Ti with Qwen3‑8B, Meta‑Llama‑3‑8B‑Instruct, and Meta‑Llama‑3.1‑8B‑Instruct showed Qwen3‑8B’s think mode slows generation, while Llama‑3‑8B is weaker overall. We chose Meta‑Llama‑3.1‑8B‑Instruct for a quality–efficiency balance and generated ≈45k English names with attributes, carefully controlling template randomness and deduplicating triples.
- Replacing the sentence encoder. The original used OpenAI ada‑002 (1536‑d). In our setting we use open‑source all‑MiniLM‑L6‑v2 (384‑d). We re‑initialized the linear adapters and added normalization to match the LLM’s key/value dims. We’re also evaluating other English embedding models:
- BGE‑base‑en‑v1.5 (strong retrieval with hard negatives; prefix support)
- E5‑base‑v2 (balanced performance; no prefix required)
- nomic‑embed‑text‑v1 (longer inputs, multilingual; larger model)
- all‑mpnet‑base‑v2 and gtr‑base (768‑d, commonly used for QA retrieval)
We’ll benchmark these and pick the best for ≈45k triples. Reports indicate swapping encoders doesn’t hurt KBLaM retrieval if adapters are retrained.
Table 1. Comparison of open‑source embedding models
| Model | Architecture | Dim | Pros | Cons |
|---|---|---|---|---|
| all‑MiniLM‑L6‑v2 | MiniLM (6L) | 384 | Lightweight, fast | Longer‑sentence performance |
| BGE‑base‑en‑v1.5 | BERT | 768 | Strong retrieval; prefixable | Larger; needs prefixes |
| E5‑base‑v2 | RoBERTa | 768 | Balanced; no prefixes | Truncation on long texts |
| nomic‑embed‑text‑v1 | GPT‑style | ≈1024 | Long inputs; multilingual | Large; slower |
| all‑mpnet‑base‑v2 | MPNet | 768 | High‑quality retrieval | Higher resource needs |
- LLM adaptation and memory management. We verified Llama‑3‑8B‑Instruct on a personal PC (Windows + RTX 2080 Ti). For the server (32 GB per 910B card), we plan 8‑card model parallelism with ZeRO‑2 and FP16 weights, converting HF weights to MindSpore‑CKPT. To support rectangular attention, we will re‑implement kernels such as
masked_addandsoftmaxin MindSpore and tune batch sizes for speed/memory. - Ecosystem compatibility. Kylin v10 lacks some DL deps and conflicts with Ascend CANN versions. We compiled MindSpore 2.2 and Ascend‑adapted PyTorch 2.0, linked libcann manually, adjusted
LD_LIBRARY_PATH, and mirrored Python packages to an internal index to complete installation offline.
With these optimizations, we reproduced the main KBLaM experiments on a PC and are generating ≈45k names and 135k synthetic triples, training adapters and validating results. Next, we’ll move the flow to the 910B server, test rectangular attention and memory, and improve KB construction and fine‑tuning.
III. Next Training Plan
To raise performance and validate broader scenarios, we will follow a staged plan:
- Multi‑stage training
- Stage 1 (baseline): Train adapters on ≈45k synthetic English triples. Single‑card batch size 32; ~30k steps; evaluate retrieval accuracy, BERTScore, and refusal rate.
- Stage 2 (expand KB): Grow the KB to 50k, 100k+; train under 8‑card data parallelism; verify rectangular attention scalability; track memory and latency.
- Stage 3 (relations and multi‑hop): Build knowledge graphs with inter‑entity relations; design single‑/multi‑hop and conflict‑reasoning tasks; extend instructions to elicit chain‑of‑thought–style explanations.
- Embedding model bake‑off: Support BGE/E5/nomic/mpnet families in code, train/evaluate on the same KB, and compare retrieval and reasoning quality.
- Memory and speed analysis: Increase KB size in batches (1k→10k→50k→100k), record memory/latency curves on Ascend NPUs, and quantify answer stability across KB scales.
IV. Chinese Localization Plan
KBLaM’s reference implementation targets English. For Chinese deployment we propose:
- Chinese KB construction: Use Chinese encyclopedias or enterprise docs; perform IE and entity linking to yield triples. Define domain‑specific entity/attribute sets beyond simple “description/purpose”, and include counterfactual or conflicting attributes to test robustness.
- Chinese sentence encoders: Choose encoders trained on large Chinese corpora (e.g., bge‑large‑zh, sent‑bert‑zh); run them with Ascend‑PyTorch; fine‑tune when necessary.
- Chinese LLM and adapters: Use open‑source Chinese LLMs (e.g., ChatGLM3, Yi‑34B). Re‑train adapters to match vocab/positional differences. Instruction templates should be native Chinese, e.g., "Please explain the purpose of...", "Unable to find relevant information in the knowledge base."
- Multi‑hop reasoning and chain explanations: Include inter‑entity relations; design questions that require composing multiple tokens and produce explicit reasoning chains.
- Evaluation and safety: Beyond accuracy, stress‑test robustness and safety with noise/conflicts; sanitize sensitive knowledge to avoid leakage during generation.
V. Improvements and Future Directions
- Hierarchical retrieval and mixtures: Treat knowledge tokens as an index: first coarse retrieval with FAISS/Annoy (dense/sparse), then fine re‑ranking via rectangular attention; or introduce a gating network to activate only relevant knowledge blocks inside the LLM (MoE‑like), lowering compute while improving quality.
- Structure‑preserving encoding: Move beyond fixed‑length pooling of “name+property” and “value”. Explore variable‑length sequence–graph encoders so tokens carry structural info (order, numbers, relations) and support multi‑hop reasoning.
- Adaptive compression and selection: Learn per‑token dimensional budgets based on frequency, confidence, or domain relevance; skip injection for irrelevant items; borrow deformable‑attention‑style sampling to reduce compute.
- Richer instruction tuning and chain‑of‑thought: Expand from single‑hop QA to multi‑hop, conflict detection, counterfactual queries, and rationale generation, using staged training and CoT/think prompts as supervision.
- External tools and verification: Add a fact‑checking module at the end of generation (SPARQL/graph reasoning); use self‑consistency over the selected tokens; optionally combine with document/web retrieval to cross‑check facts.
- Domain adaptation and open/closed models: Build domain KBs and instruction sets; pick focused LLMs (e.g., FinGPT/MedGPT) or use API proxies while keeping the KB local.
- Chinese and multilingual expansion: Use multilingual encoders (e.g., multi‑qa‑mpnet‑base‑dot‑v1, gtr‑xxl) to map triples into a unified space, enabling cross‑lingual retrieval and generation, with language tags stored in tokens and conditional adapters per language.
Conclusion
KBLaM shows a promising end‑to‑end path to weave external knowledge into LLMs via knowledge tokens and rectangular attention. Despite challenges in offline, heterogeneous hardware, and Chinese localization, by swapping encoders and LLMs, re‑writing kernels, and designing local synthetic data, we validated KBLaM’s feasibility and planned the next training phase. With advances in hybrid retrieval, structural encoders, adaptive compression, and chain‑style reasoning, KBLaM can become an efficient bridge between knowledge bases and LLMs for enterprise knowledge management and QA.
References
[1] Taketomo Isazawa, Xi Wang, Liana Mikaelyan, Mathew Salvaris, James Hensman. “KBLaM: Knowledge Base Augmented Language Model.” Proceedings of 2025.
[2] Survey on knowledge‑base augmented LLMs. 2023.
[3] Naman Bansal. “Best Open‑Source Embedding Models Benchmarked and Ranked.” Supermemory Blog, 2025.
[4] Microsoft Research. “Introducing KBLaM: Bringing plug‑and‑play external knowledge to LLMs.” Microsoft Research Blog, 2025.