
En los últimos meses hemos desplegado, depurado y estudiado a fondo KBLaM (Knowledge Base augmented Language Model). Propuesto por Microsoft Research en 2025, KBLaM inyecta conocimiento estructurado directamente en un LLM preentrenado mediante un codificador de oraciones y adaptadores lineales. Convierte la base de conocimiento en vectores continuos clave‑valor (tokens de conocimiento) y los fusiona con el LLM mediante una atención rectangular modificada, lo que permite responder sin recuperación externa. Este artículo revisa los principios y experimentos de KBLaM, resume la experiencia de despliegue en servidores nacionales, presenta el plan de entrenamiento, discute la localización al chino y propone líneas de mejora.
I. Revisión de la teoría y los experimentos de KBLaM
1.1 Diseño del modelo
La idea central es mapear las tripletas de la base de conocimiento $\langle \text{name},\,\text{property},\,\text{value} \rangle$ a vectores del tamaño de la caché clave‑valor del LLM, llamados tokens de conocimiento. El proceso es:
- Codificación del conocimiento. Un codificador $f(\cdot)$ mapea “name y su property” y “value” a $k_m = f(\text{property}_m\,\text{of}\,\text{name}_m)$ y $v_m = f(\text{value}_m)$. Adaptadores lineales los proyectan a los espacios de clave/valor de cada capa: $\tilde{k}_m = \tilde{W}_K k_m$, $\tilde{v}_m = \tilde{W}_V v_m$. Cada token de conocimiento contiene vectores para $L$ capas.
- Atención rectangular. En inferencia, el modelo alimenta $N$ tokens del prompt y $M$ tokens de conocimiento. Para evitar $O((N+M)^2)$, los tokens de conocimiento no se atienden entre sí; los tokens del prompt pueden atender a anteriores y a todos los de conocimiento, formando una matriz $(M+N)\!\times\!N$. La salida $\tilde{y}_n$ suma: (a) valores del conocimiento ponderados por la similitud entre consulta y claves del conocimiento, y (b) autoatención entre tokens del prompt. El costo crece linealmente con $M$, ventajoso cuando $M\gg N$.
- Ajuste instruccional con KB. Dado el desfase semántico entre codificador y LLM, el paper entrena solo los adaptadores lineales y una cabeza de consulta, maximizando $\log p_\theta(A\mid Q,KB)$ con una KB sintética (≈45k nombres, 135k tripletas) y sin tocar los pesos del LLM. Con AdamW durante 20k pasos en una A100, el modelo aprende a recuperar y a negarse cuando no hay evidencia.
Para entender el flujo, la Figura 1 muestra las fases offline/online: offline se construye y codifica la KB; online la atención rectangular fusiona prompt y conocimiento antes de generar. El siguiente seudocódigo ilustra una capa de atención:
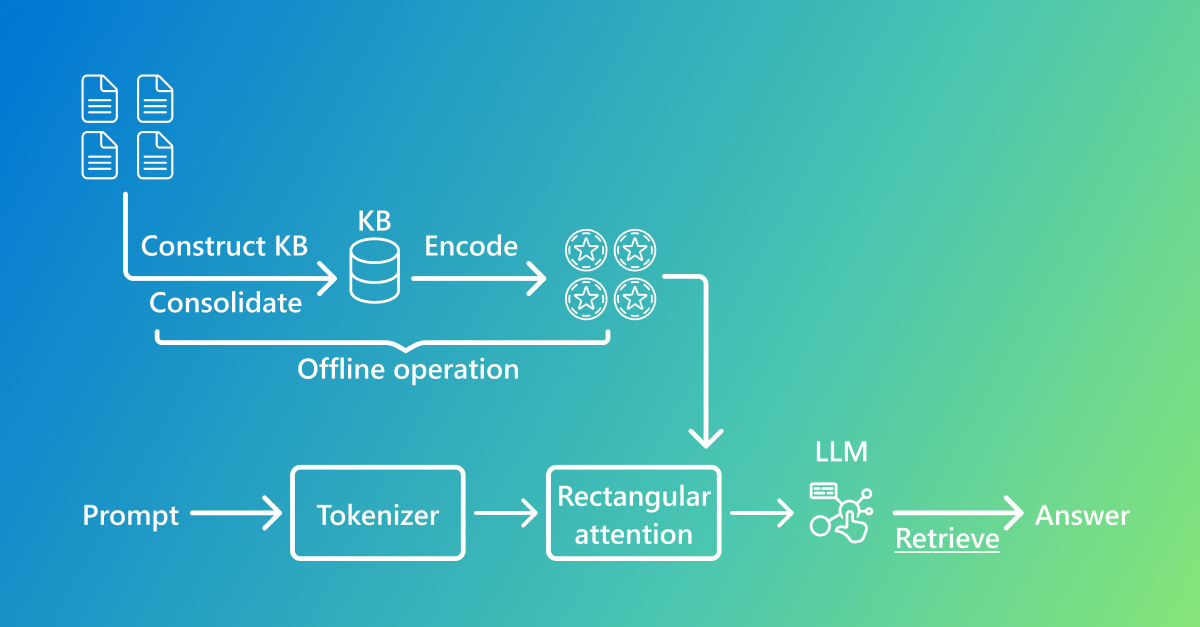
Figura 1. Offline: construir/codificar la KB para generar tokens de conocimiento. Online: atención rectangular + LLM para responder.
1.3 Seudocódigo de atención rectangular
def rectangular_attention(Q, K_kb, V_kb, K_text, V_text):
"""
Q: matriz de consulta de los tokens del prompt, forma (N, d)
K_kb, V_kb: claves/valores del conocimiento, forma (M, d)
K_text, V_text: claves/valores de autoatención del prompt
Devuelve: salida fusionada conocimiento + prompt
"""
# Atención sobre tokens de conocimiento
attn_kb = softmax(Q @ K_kb.T / sqrt(d))
output_kb = attn_kb @ V_kb
# Autoatención entre tokens del prompt
attn_text = softmax(Q @ K_text.T / sqrt(d))
output_text = attn_text @ V_text
# Suma de ambas partes
return output_kb + output_text
1.2 Resultados experimentales
- Precisión e interpretabilidad en recuperación. Las puntuaciones de atención actúan como señales implícitas de recuperación: las palabras de la pregunta se enfocan en los tokens correctos. En conjuntos sintéticos y Enron, KBLaM mantiene top‑1/top‑5 precisos con KBs grandes.
- Calidad en QA. En QA de respuesta corta, multi‑entidad y abierta, la calidad (BERTScore o GPT‑4) iguala a concatenar todas las tripletas en contexto, con mucha menos memoria. Con >10k tripletas, el aprendizaje en contexto es inviable por memoria $O((KN)^2)$, mientras KBLaM sigue estable.
- Comportamiento de negativa. KBLaM detecta cuando la KB carece de evidencia y se niega educadamente; la tasa de falsas negativas crece más lento que en el enfoque en contexto.
- Limitaciones. Vectores de longitud fija pierden números/nombres exactos; las KB sintéticas no siempre reflejan la distribución real; queda trabajo en multi‑salto, compresión controlable y construcción a partir de datos reales.
II. Despliegue en servidores nacionales
Nuestro entorno usa Kylin v10 y ocho NPUs Ascend 910B sin acceso a Internet. Esto difiere del entorno GPU + GPT/ada‑002 del paper, por lo que adaptamos:
- Generación de KB e instrucciones. Sin OpenAI, usamos LLMs locales offline. En Windows + RTX 2080 Ti probamos Qwen3‑8B, Meta‑Llama‑3‑8B‑Instruct y Meta‑Llama‑3.1‑8B‑Instruct; elegimos Meta‑Llama‑3.1‑8B‑Instruct por equilibrio calidad‑eficiencia y generamos ≈45k nombres con atributos, controlando aleatoriedad y deduplicación.
- Sustitución del codificador de oraciones. En lugar de ada‑002 (1536‑d), usamos all‑MiniLM‑L6‑v2 (384‑d), re‑inicializando adaptadores y normalización. Evaluamos además:
- BGE‑base‑en‑v1.5, E5‑base‑v2, nomic‑embed‑text‑v1, all‑mpnet‑base‑v2, gtr‑base.
Elegiremos el mejor para ≈45k tripletas. Estudios señalan que, re‑entrenando adaptadores, cambiar el encoder no degrada la recuperación.
Tabla 1. Comparativa de modelos de incrustación open‑source
| Modelo | Arquitectura | Dim | Pros | Contras |
|---|---|---|---|---|
| all‑MiniLM‑L6‑v2 | MiniLM (6L) | 384 | Ligero, rápido | Peor en oraciones largas |
| BGE‑base‑en‑v1.5 | BERT | 768 | Recuperación fuerte; prefijos | Modelo más grande |
| E5‑base‑v2 | RoBERTa | 768 | Equilibrado; sin prefijos | Truncamiento en textos largos |
| nomic‑embed‑text‑v1 | Tipo GPT | ≈1024 | Entradas largas; multilingüe | Grande; más lento |
| all‑mpnet‑base‑v2 | MPNet | 768 | Recuperación de alta calidad | Más demanda de recursos |
- Adaptación del LLM y memoria. Verificamos Llama‑3‑8B‑Instruct en PC personal; en servidor (32 GB por 910B) planeamos paralelismo en 8 tarjetas con ZeRO‑2 y FP16, convirtiendo pesos HF a MindSpore‑CKPT. Para la atención rectangular re‑implementaremos
masked_addysoftmaxen MindSpore y ajustaremos lotes. - Compatibilidad del ecosistema. Kylin v10 carece de algunas dependencias y choca con CANN. Compilamos MindSpore 2.2 y PyTorch 2.0 adaptado a Ascend, enlazamos libcann y ajustamos
LD_LIBRARY_PATH, usando un índice interno de paquetes.
Con lo anterior, reproducimos los principales experimentos en PC y estamos generando ≈45k nombres y 135k tripletas sintéticas, entrenando adaptadores y validando. Después migraremos el flujo al servidor 910B, probaremos atención rectangular y memoria, y afinaremos la construcción de KB y el fine‑tuning.
III. Plan de entrenamiento
- Entrenamiento en etapas
- Etapa 1 (línea base): Adaptadores sobre ≈45k tripletas. Lote 32 por tarjeta; ~30k pasos; métricas de recuperación, BERTScore y tasa de negativa.
- Etapa 2 (ampliar KB): 50k, 100k+; paralelismo de datos en 8 tarjetas; escalabilidad de la atención rectangular; memoria y latencia.
- Etapa 3 (relaciones y multi‑salto): Grafo de conocimiento con relaciones; tareas de uno/múltiples saltos y conflictos; explicaciones tipo cadena de pensamiento.
- Comparativa de encoders: Soportar BGE/E5/nomic/mpnet/gtr, entrenar y evaluar en la misma KB y comparar calidad de recuperación/razonamiento.
- Memoria y velocidad: Aumentar el tamaño de la KB por lotes (1k→10k→50k→100k), registrar curvas de memoria/latencia en NPUs Ascend y estabilidad de respuestas.
IV. Localización al chino
- Construcción de KB en chino: Enciclopedias/documentos empresariales; extracción de información y enlace de entidades para generar tripletas; listas de entidades/atributos por dominio; incluir atributos conflictivos para pruebas.
- Codificadores chinos: bge‑large‑zh, sent‑bert‑zh; inferencia con Ascend‑PyTorch; fine‑tuning cuando sea necesario.
- LLM y adaptadores chinos: Modelos chinos open‑source (ChatGLM3, Yi‑34B); re‑entrenar adaptadores por diferencias de vocab/posicional; plantillas de instrucción en chino natural (p. ej., "Por favor explica el uso de...", "No se puede encontrar información relevante en la base de conocimiento").
- Razonamiento multi‑salto y explicaciones: Incluir relaciones entre entidades; preguntas que requieran componer varios tokens y producir cadenas explicativas.
- Evaluación y seguridad: Además de precisión, robustez ante ruido/conflictos; desensibilizar conocimiento sensible para evitar filtraciones.
V. Mejoras y líneas futuras
- Recuperación jerárquica y mezclas: Usar tokens de conocimiento como índice (coarse con FAISS/Annoy y reranking con atención rectangular) o una red de compuertas (estilo MoE) para activar solo bloques relevantes.
- Codificación que preserve estructura: Más allá del pooling fijo, explorar codificadores secuencia‑grafo de longitud variable que conserven orden, números y relaciones, favoreciendo el razonamiento multi‑salto.
- Compresión y selección adaptativas: Presupuestos de dimensión por token según frecuencia/confianza/relevancia; saltar inyecciones irrelevantes; muestreo tipo atención deformable para reducir cómputo.
- Ajuste instruccional rico y cadena de pensamiento: De QA de un salto a multi‑salto, conflictos, contrafactuales y explicaciones, con entrenamiento por etapas y plantillas CoT.
- Herramientas externas y verificación: Módulo de verificación factual (SPARQL/grafo); auto‑consistencia sobre tokens seleccionados; combinar con recuperación de documentos/web cuando convenga.
- Adaptación por dominio y modelos abiertos/cerrados: KBs e instrucciones por dominio; LLMs enfocados (FinGPT/MedGPT) o APIs manteniendo la KB local.
- Expansión al chino y multilingüe: Encoders multilingües (multi‑qa‑mpnet‑base‑dot‑v1, gtr‑xxl) para un espacio unificado; etiquetas de idioma en tokens y adaptadores condicionales por idioma.
Conclusión
KBLaM ofrece una vía end‑to‑end para entretejer conocimiento externo en LLMs mediante tokens de conocimiento y atención rectangular. Pese a retos de entorno offline, hardware heterogéneo y localización al chino, al sustituir codificadores/LLMs, re‑escribir kernels y diseñar datos sintéticos locales, validamos la viabilidad de KBLaM y planificamos la siguiente fase. Con avances en recuperación híbrida, codificación estructural, compresión adaptativa y razonamiento en cadena, KBLaM puede ser un puente eficiente entre bases de conocimiento y LLMs para la gestión del conocimiento y el QA.
Referencias
[1] Taketomo Isazawa, Xi Wang, Liana Mikaelyan, Mathew Salvaris, James Hensman. “KBLaM: Knowledge Base Augmented Language Model.” Proceedings of 2025.
[2] Revisión de LLMs aumentados con bases de conocimiento. 2023.
[3] Naman Bansal. “Best Open‑Source Embedding Models Benchmarked and Ranked.” Supermemory Blog, 2025.
[4] Microsoft Research. “Introducing KBLaM: Bringing plug‑and‑play external knowledge to LLMs.” Microsoft Research Blog, 2025.